Hopper 屏障探秘
这两天发现可以在 LeetGPU 玩 H100,刚好就来学一下 Hopper 架构。
在使用 Hopper 架构时,一个绕不开的部分是屏障(PTX: mbarrier, SASS: SYNCS)。
在使用 Hopper 的 TMA 读取全局内存,以及 Flash Attention 3 的 pingpong 调度时,都离不开屏障的使用。在后续的 Blackwell 架构中,tcgen05.mma指令也需要使用屏障进行同步。
然而,屏障是一个较为复杂的模块,并且现有的 PTX 文档中对于屏障具体的语义并没有详细说明,现有的代码库中的用法也多种多样,因此有必须详细了解屏障的内部实现。
Ampere 架构
在 Ampere 架构中,异步相关的概念实际上已经成熟,只是相关的硬件设计还没有定型,因此只简单(挤牙膏)地实现了一部分的硬件。Ampere 架构中,唯一异步的功能是读取全局内存到共享内存时,可以使用异步拷贝(PTX: cp.async, SASS: LDGSTS)将全局内存的数据读取到共享内存中。这一功能除了可以大大节省寄存器的占用外,还可以突破默认的寄存器依赖关系,实现大于 2 级的流水线。
异步编程的对立面是同步编程。在同步的编程模型中,所有用到的数据依赖关系可以直接从 CUDA 代码中得出,编译器和硬件根据数据流,自动地等待所需要的数据。而在异步的编程模型中,数据依赖关系无法由 CUDA 代码推出,并且需要在代码中特意指出某些指令在特定的时刻存在依赖关系。在使用异步拷贝时,可以使用的同步方法有:
- 直接阻塞:发起若干次异步拷贝的指令后,调用阻塞指令直接在本线程中等待(部分)异步拷贝指令完成。
- 基于屏障:发起若干次异步拷贝的指令后,指示异步拷贝控制屏障到达(arrive-on),再等待屏障完成(complete)。
直接阻塞
直接阻塞的编程方法直接简单:
// 发射若干条异步指令
cp.async; // 省略具体参数,下同
cp.async;
// 创建指令组
cp.async.commit_group; // LDGDEPBAR
// 等待指令完成
cp.async.wait N; // DEPBAR.LE
上述的三条指令都是线程级别的。也就是说,上面发射的异步拷贝、创建的指令组、等待指令完成都是在本线程的范围内进行的,即使硬件实现时显然需要以 warp 为单位进行管理,在软件上暴露的抽象仍然是线程级别的。因此,在执行完成后,如果需要实现整个线程块级别的同步,通常还需要进行一次线程间的同步(__syncthreads)。
创建指令组一步,应该只是用于省去手动计算到底发射了几条指令,并不影响功能的执行。实际的异步拷贝功能在发射后立刻执行,并不是像工作中的“提交”一样,要在提交之后才会去做。因此,cp.async.commit_group和cp.async.wait一般都连着写。
等待指令完成时,可以指定最后 N 组指令未完成。N 组正在进行的指令,再加上一组刚刚才提交的,以及一级正在使用的,可以构成 N+2 级流水。
后续 Hopper 架构中,Tensor Core 以及 TMA 写回全局内存时,都使用直接阻塞的方法进行同步。
基于屏障
直接阻塞的方法是 Ampere 架构上使用异步拷贝最简单也最常用的方法,但是估计是为了测试性能,硬件上还同时支持基于屏障的同步方法。后续 Hopper 架构中不再有这种支持多种同步方法的功能,每个功能都有分配好的唯一一种同步方法,例如 TMA 读取全局内存时,为了方便 Warp specialization,仅支持基于屏障同步。
具体的编程方法是:
// 发射若干条异步指令
cp.async;
cp.async;
cp.async.mbarrier.arrive.shared.b64 [bar];
通过cp.async.mbarrier.arrive指令,可以在这一组异步拷贝完成后,由硬件异步执行屏障bar的到达操作。这条指令隐含了创建指令组,不需要再执行cp.async.commit_group。换一种角度,可以理解为将这个线程本身的到达操作推迟到了异步拷贝真正完成时才进行,因此这也是一个线程级别的语义。
显然,屏障bar需要初始化,并且在后面合适的时候进行同步,这些内容后面介绍。
基本语义
前面多次提到屏障,那么屏障具体的含义是什么呢?
- 使用
mbarrier.init和mbarrier.inval初始化和反初始化屏障。初始化时,需要指定屏障完成对应的到达次数。 - 每个线程可以使用
mbarrier.arrive来执行一次对应屏障的到达操作。每线程的cp.async.mbarrier.arrive对应的异步拷贝组每次完成时,也会执行一次到达。 - 每个线程使用
mbarrier.try_wait或者mbarrier.test_wait来等待屏障完成。 - 为了适配 TMA,每个屏障可以执行
mbarrier.expect_tx指令,指示这个屏障本次完成前需要额外等待若干字节的 TMA 传输。和前面cp.async.mbarrier.arrive类似,mbarrier.expect_tx通常会融进mbarrier.arrive,组成mbarrier.arrive.expect_tx。
可以看出,屏障用于保证代码在指定次数的到达和 TMA 传输后才进行。因此,屏障的使用基本过程为:
- 使用
mbarrier.init初始化,设置到达数为 N,极性 0。 - 如果有需要,执行
mbarrier.expect_tx,设置等待的 TMA 的字节数 M。 - 等待 N 次
mbarrier.arrive执行完毕,并且 TMA 传输 M 字节也完毕。 - 此时屏障到达,重置到达数为 N,等待的 TMA 字节数重置为 0,极性反转。
这里的极性(phase/polarity)是一个不得不泄露的硬件抽象。理想的抽象是,屏障有完成和未完成两个状态,初始为未完成,一定条件满足后为完成。但一个完成的屏障如何恢复为未完成呢?我们不能在某次操作后就自动置该屏障为未完成,毕竟我们不知道到底别的线程是否仍然依赖于该屏障的状态。因此,我们必须要在适当的时候软件发射一个重置屏障的指令。
而一个更好的方法是我们不发射重置指令,而简单地在软件置一个布尔值,用来决定到底 0 和 1 哪个表示完成。
或者,能不能把极性不同的一个屏障用作两个用途呢?例如 TMA 传输时通常需要两个屏障,一个表示空,一个表示满,能不能用一个屏障解决?
需要注意,由于等待 TMA 字节数默认为 0,因此到达次数不能也为 0,否则一个屏障就会自动不同地完成。因此,使用 TMA 时,总还是需要让 TMA 线程本身执行一次到达。
// 一共 N 个线程,其中 1 个发射 TMA
mbarrier.init.shared.b64 [bar], N;
// TMA 线程:
// 发射 TMA 指令
cp.async.bulk ..., [bar];
// 设置等待 TMA 字节数,然后到达
mbarrier.arrive.expect_tx _, [bar], txCount;
// 其他线程:直接到达
mbarrier.arrive _, [bar];
// 访问 TMA 读取的数据前:等待屏障完成
waitLoop:
mbarrier.try_wait p, [bar], phase;
@!p bra waitLoop;
从上述的代码中可以看到,进行 TMA 的同步时,所选用的到达数是相当随意的。而其中最简单的指定方法是把 N 设为 1,否则还得操心到达另外还有多少个线程也到达了。ThunderKittens 和 DeepGEMM 中部分代码也是采取了这个设计,而在 CUDA C++ Programming Guide 中则设置了 127 个围观线程。这应该只是两者代码风格的区别,不构成功能区别。
硬件实现
在 Hopper 中,屏障可以说是相当忙碌的一个组件了,需要处理各个线程、TMA、其他 SM 中的大量同步信息。但是,这么一个复杂的组件,竟然分配在共享内存中,这合理吗?
一点都不合理!在 Ampere 架构中,虽然有了对应的 PTX 命令,但是所有的操作真的是通过读取共享内存来完成的:
- 初始化屏障是直接
STS向共享内容写入对应的内容。 - 到达有一个特殊的
ATOMS.ARRIVE.64,没测过具体是线程级还是 warp 级。 - 不支持
mbarrier.try_wait,只能用YIELD+NANOSLEEP+LDS模拟屏障实现。
可以看到整个过程对共享内存的负担很大,占据了本就不宽裕的共享内存带宽,这样的硬件设计是不可能支持后续 Hopper 中大量使用屏障的同步机制的。
那么 Hopper 的屏障如何实现呢?我们没有内部文档,但是英伟达的专利 US17/691,296 Hardware accelerated synchronization with asynchronous transaction support 公开了相当多的内部实现细节,让我们得以管中窥豹。
在 Hopper 中,mbarrier系列 PTX 用到的 SASS 指令有专属的 SYNCS 前缀,意为同步单元,其中 S 表示共享内存。图中虚线框中的就是这个同步单元。
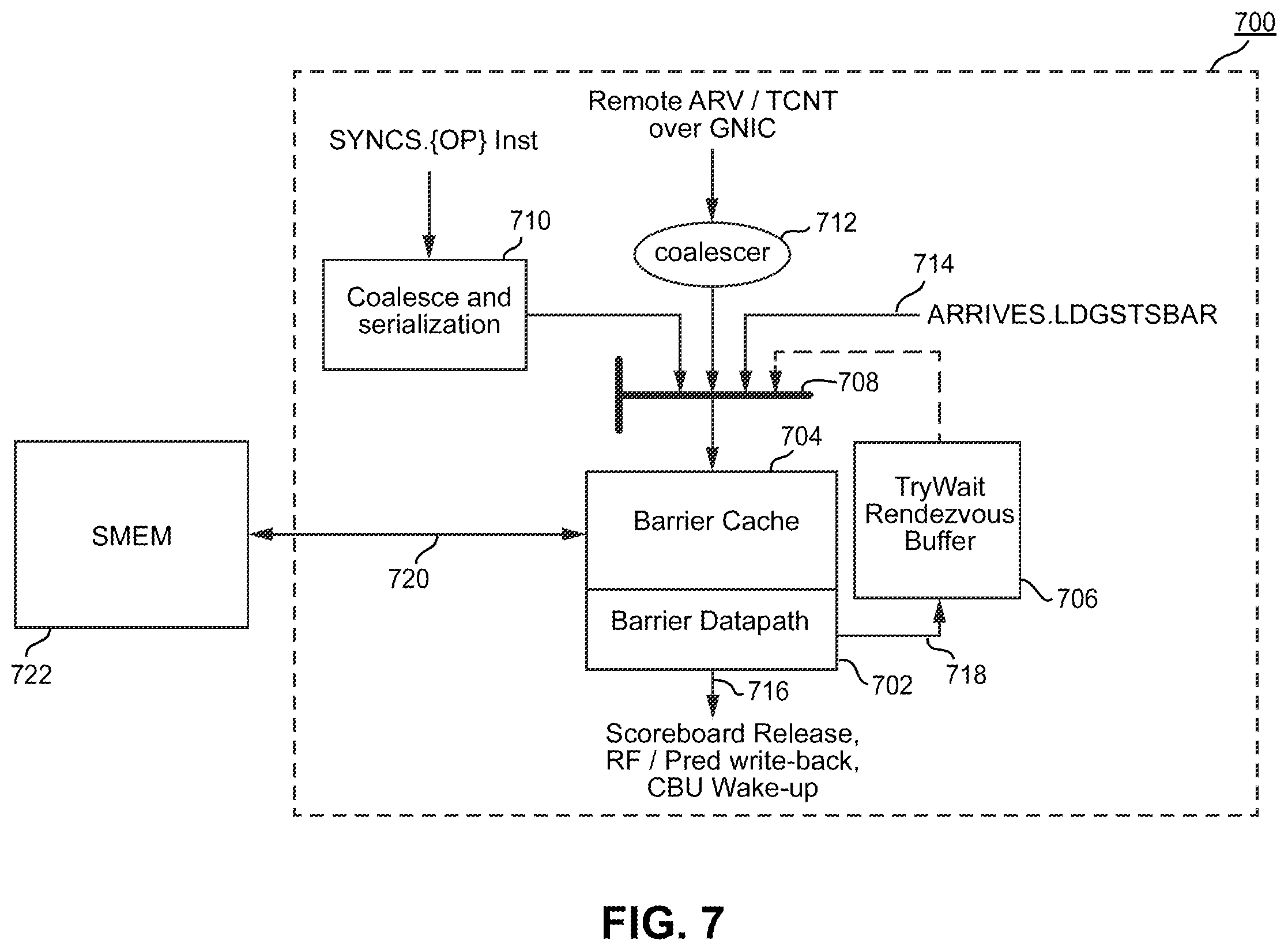
这个同步单元在实现屏障方面起到至关重要的作用。
- 减少共享内存流量。同步单元的屏障缓存(704)中可以容纳 4 个屏障,作为对应共享内存中屏障的缓存,所有的屏障相关指令先进入缓存,在缓存溢出时才会发出共享内存流量。同时,屏障指令本身进入同步单元后,也会进行内部的合并,减少内部的流量。
- 支持阻塞调度。图中的 try-wait buffer(706)可以储存 32 个请求,用于在对应的屏障完成后,利用相关的数据通路(716)触发 SM 中相关的控制流。
- 处理远程同步指令。TMA 的设计关联着多种 SM 间直连的流量(Cooperative Group Array 和 Distrubuted Shared Memory),这些来自其他 SM 的同步指令,也经过同步单元进行处理。
另外,同步单元中储存的屏障为 257 位,比共享内存中的 64 位要多,而且还有对应的 try-wait buffer 内容想必也是针对在缓存中的 4 个屏障才有效。因此,当一个屏障要逐出缓存时,需要丢弃大量的信息,相关的指令可能会失败。这使得在 Hopper 中,屏障等待操作也是不保证成功的,同样需要重试的逻辑。